Sommaire
Sujet récurrent dans HA et la domotique en général : comment sont gérées les données historiques . Cela peut interpeller les nouveaux arrivants d'un système domotique avec une base de données centrale.
La bonne gestion de la base de données a une importance capitale, surtout lorsque votre installation grandit. Le mieux est de ne pas attendre et de commencer sur de bonnes bases, pour éviter une base de données avec une taille trop importante, des mises à jour et restaurations volumineuses et lentes, une mauvaise stabilité du système...
Je vais présenter ici les généralités des deux grands types de données dans HA : le recorder et les statistiques.
Les données dans HA
Le Recorder : les données récentes détaillées.
Le recorder est le système principal d'enregistrement de HA. Il stocke les états, les évènements et les attributs de toutes vos entités présentes dans HA, ainsi que leurs historiques récents (juste les 10 derniers jours par défaut). Au-delà, les données sont purgées et agrégées dans les statistiques.
Le recorder permet l'affichage des graphiques historiques sur les tableaux de bord et d'autres fonctionnalités liées à l'évolution des valeurs. En fonction de la fréquence de mise à jour de chacun de vos appareils et le nombre de jours gardés en mémoire, cette base de données peut très vite prendre de la place.
Des configurations existent pour contrôler les enregistrements et filtrer les informations qui ne sont pas utiles.
Les statistiques : une vue plus long terme et analytique.
Pour certains types de données, comme les informations énergétiques ou pour des mesures comme les températures, HA stocke automatiquement une version plus agrégée des données et indéfiniment dans le temps. Cela permet d'avoir moins d'impact sur la taille de la base de données. Ces valeurs sont utilisables aussi pour des historiques long terme (graphiques dit "statistiques").
Les données sont traitées pour être conservés indéfiniment, mais à raison d'une seule valeur par 5 min (statistique "court terme", 10 jours par défaut) puis par heure (statistique "long terme"). Le traitement consiste à reprendre les données du recorder et à calculer le min, max, moyenne ou la somme.
La base de données
Les deux types de données partagent la même base de données. C'est par défaut une base de données SQLite. Les données sont stockées dans un fichier qui est accessible dans le répertoire "/config" et porte le nom "home-assistant_v2.db".
Un module complémentaire, SQLite Web, est disponible pour explorer la base. Des exemples d'utilisation sont donnés plus bas.
Pour ceux qui le veulent, il est aussi possible de transformer la base SQL au format MariaDB (voir MySQL ou Postgres). Il est également possible de complétement externaliser la base de données.
Configuration du recorder
La documentation officielle du recorder est très complète sur le site de HA, pour voir toutes les possibilités. N'hésitez pas à visiter la page suivante :
 Home Assistant
Home Assistant
Recommandations de base
Les données du recorder ont le plus gros impact sur la taille totale de la base de données. Une mauvaise configuration ou sa non-configuration peuvent faire exploser significativement la taille de la base, la durée des sauvegardes et potentiellement, la réactivité et la stabilité du système.
Sur un système limité en puissance comme un Raspberry ou avec un stockage lent (carte SD), la bonne configuration du recorder est donc essentielle.
Cela peut paraître limitant, mais il est fortement conseillé de garder limité la durée d'historique du recorder à 7 ou 10 jours (le défaut est 10 jours).
Pour limiter les impacts sur le stockage (surtout les cartes SD) il est recommandé d'augmenter l'intervalle de commit (paramètre commit_interval) à 30 secondes, car il est à 5 par défaut. Cette durée représente le temps entre 2 écritures sur le support, le fonctionnement de HA n'en sera pas changé, mais au moins, il accèdera 6 fois moins au stockage.
Purge
Dans HA, le Recorder est prévu pour garder de façon détaillée les états de toutes les entités pour un nombre configurable de jours. Par défaut ce nombre de jours est 10. Rester aux alentours de 10 jours est recommandé.
Toutes les nuits à 4h12, la base de données est purgée, toutes les données plus anciennes que le nombre de jours configuré sont supprimés.
On observe donc en général, un maintien de la taille moyenne de la base de données, tant que de nouvelles entités ne sont pas ajoutées.
Inclusion / Exclusion
Pour contenir la taille de la base de données, il est possible de contrôler quelles entités sont prises en compte dans le recorder. Plusieurs niveaux de filtrage sont possibles et présentés ci-dessous.
Domaines / Globs / Entités / Événements
Il est possible de configurer ceci par exclusion, par inclusions ou les deux.
Le filtrage se fait à différents niveaux :
- Domains : pour exclure ou inclure tout un type d’entités. (sensor, update, device_tracker, …)
- Entity_Globs : Pour sélectionner plusieurs entités en utilisant une expression régulière. Exemple : « sensor.freebox_* » pour exclure toutes les entités commençant par « sensor.freebox ».
- Entities : Pour sélectionner des entités spécifiquement par leur nom.
- Event_types : Pour ne pas enregistrer certains évènements. (le stockage évènements a considérablement été revu par HA, rendant cette option plus vraiment utile.)
Précédence
La combinaison des différents niveaux de filtrage ainsi que l’inclusion et l’exclusion introduit des règles dites de "précédence". Par exemple :
- Si aucun filtre n’est configuré : toutes les entités sont stockées.
- Si uniquement des inclusions sont configurées : Seules les entités correspondantes sont stockées, tout le reste ne l’est pas.
- Si seulement des exclusions sont configurées : Les entités correspondantes seront exclues, toutes les autres seront stockées.
- Un mix d’inclusions et d’exclusions réagira de façon différente en fonction du type de filtres.
Home AssistantExemple de configuration
Une méthode radicale est d'ajouter pas mal d'exclusions pour commencer, quitte à perdre certaines données, mais ensuite ajouter des entités spécifiquement.
Pas mal d'infos ne sont pas nécessaires généralement, par exemple garder l'historique de signal wifi ou autres valeurs de diagnostic n'apporte rien ou pas grand-chose, certains appareils mettent ces données à jour toutes les 10 secondes... générant ainsi une pollution évitable de la base.
recorder:
commit_interval: 30
purge_keep_days: 7
include:
entities:
- sensor.alarm_status
- device_tracker.pixel_4a
- device_tracker.voiture_location_tracker
exclude:
entities:
- sensor.spa_last_ping
- sensor.shelly_plug_s_puissance
- sensor.thermo_bureau_battery
domains:
- device_tracker
- update
- camera
event_types:
- call_service
- zwave_js_event
- shopping_list_updated
- rfxtrx_event
- persistent_notifications_updated
- service_registered
- component_loaded
entity_globs:
- sensor.freebox_*
- sensor.diskstation*
- sensor.synology*
- sensor.*_status
- sensor.*connect_countStatistiques Long terme
Quand une entité est configurée avec certains paramètres, HA génère donc des statistiques : une agrégation des valeurs d’état des entités, beaucoup moins volumineuses, qui permettent d’être gardées indéfiniment avec un impact limité sur la taille de la base.
Il est possible d'accéder aux valeurs des données statistiques à partie de l'onglet "Statistiques" des outils de développement.
Classe d'état
Pour que des statistiques long terme soient générées, il faut que l'entité soit définie avec une classe d'état (state_class) de type measurement, total ou total_increasing.
Il est primordial de bien les comprendre :
- Measurement : Cette classe d’état est utilisée pour les mesures instantanées, comme la température, la puissance électrique, etc. Les statistiques sont calculées avec les valeurs minimales, maximales et moyennes horaires.
- Total : Cette classe d’état est utilisée pour les valeurs cumulatives qui peuvent augmenter ou diminuer, comme le total d’énergie consommée ou produite. Les statistiques sont basées sur la somme totale des valeurs.
- Total_increasing : Cette classe d’état est similaire à total, mais elle est spécifiquement conçue pour les valeurs qui augmentent de manière monotone, comme la consommation de gaz, d’eau ou d’électricité. Si la valeur diminue, cela est interprété comme un nouveau cycle de compteur.
Ces distinctions permettent à Home Assistant de gérer et d’agréger les données de manière appropriée pour différents types de capteurs et d’applications.
Les 2 autres propriétés pour que les statistiques soient générées pour une entité sont device_class et unit.
Entités du Dashboard Énergie
Le dashboard énergie utilise exclusivement des données ayant des statistiques.
Pour qu'une entité soit utilisable dans le tableau énergie, celle-ci doit avoir les 3 caractéristiques suivantes :
| Classe d’appareil | Energie (Energy) |
| Classe d’état | Total ou Total_increasing |
| Unité | kWh (ou ésuivalent) |
Les autres entités
De manière générale, toute entité ayant un état numérique permet de générer des statistiques et donc garder un historique indéfini.
Pour cela, il faut que l'entité ait :
| Classe d’appareil | N'importe quelle classe définie |
| Classe d’état | Measurement, Total ou Total_increasing |
| Unité | N'importe quelle unité standard |
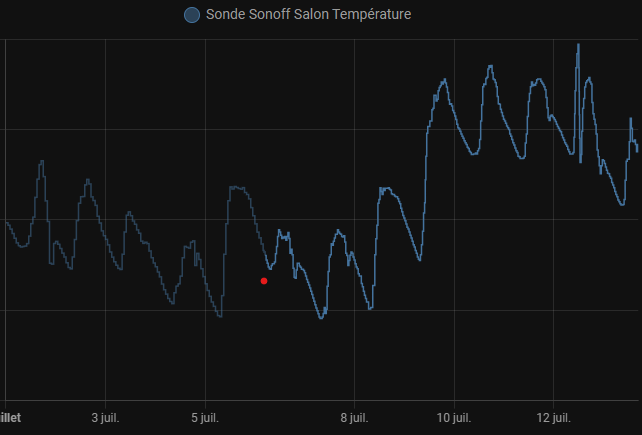
Une entité avec des statistiques permet aussi d'utiliser les cartes statistiques permettant une représentation plus analytique des données.
Il existe aussi de nombreuses solutions tierces sur le store de la communauté HACS (Apex Charts cards, mini-graph cards, History Explorer Card ....)
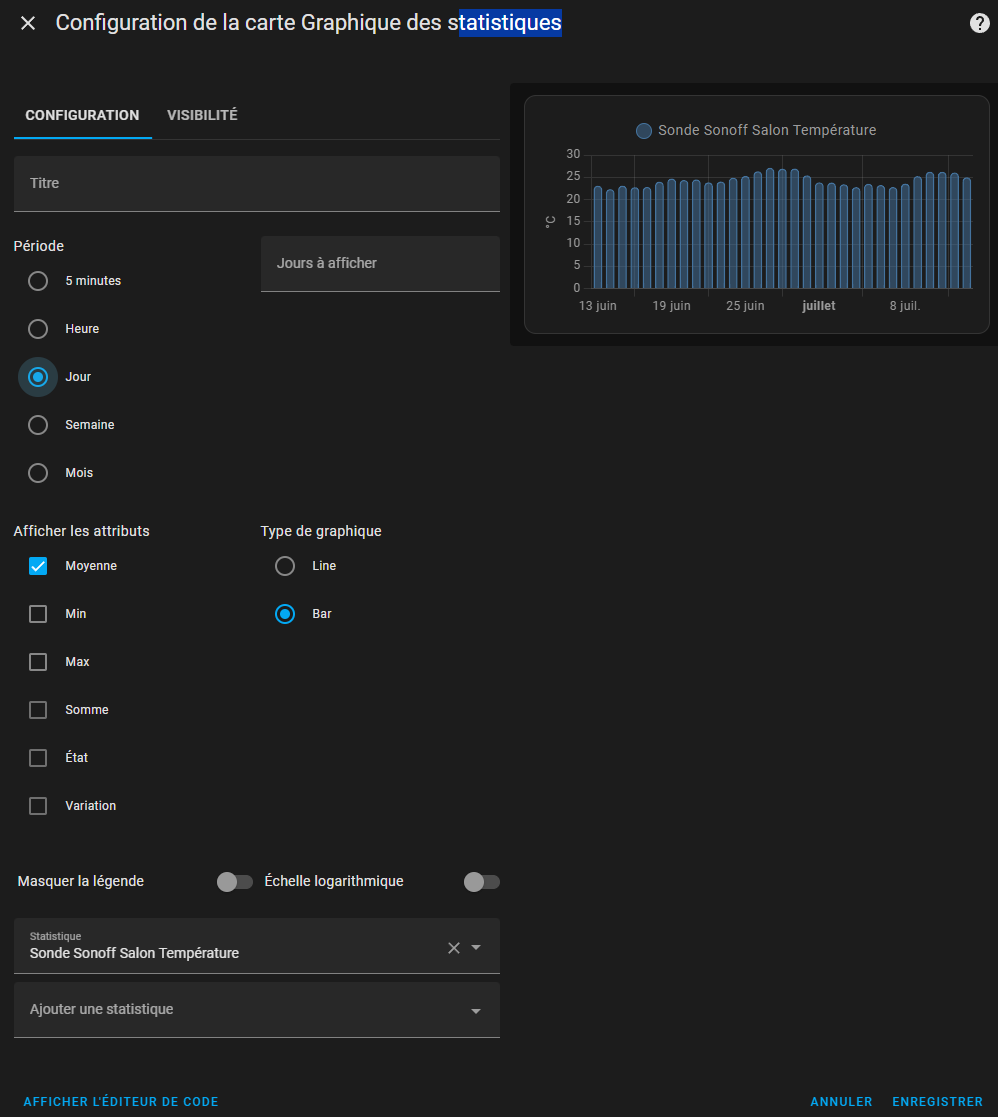
Correction des statistiques
Pour certaines raisons, souvent une intégration mal gérée, des valeurs parasites erratiques peuvent être introduites. J'ai le cas avec mon intégration Enphase qui au redémarrage de la passerelle peut envoyer la production totale de l'installation au lieu de la journalière.
Ceci peut donner un résultat disgracieux et faux au tableau énergie, les outils de développement permettent de corriger ça sans touche à la base de données.
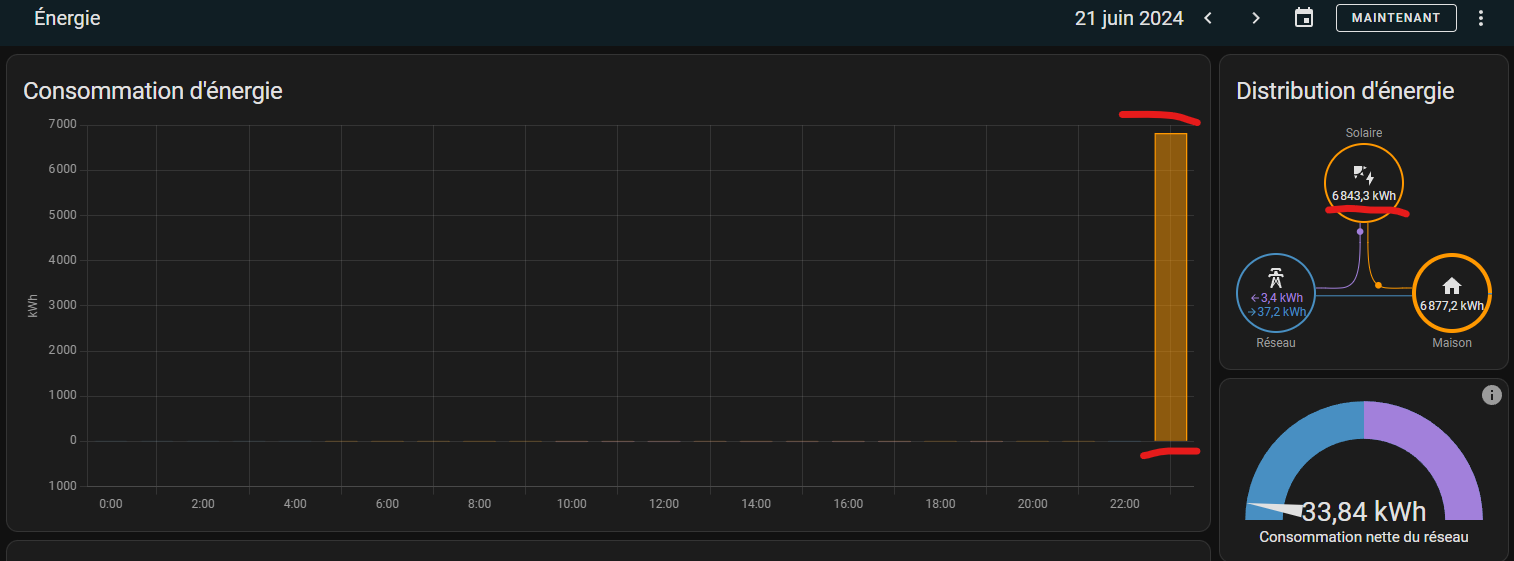
En allant dans les outils de développement, onglet statistiques et en cherchant l'entité qui fournie la valeur erratique, ici ma production solaire, on devrait voir ceci :

En cliquant sur l'icône "Ajuster", un pop-up s'ouvre, où il est possible de naviguer vers la date et l'heure en question. Les données sont stockées par trancher agrégées de 5 minutes, il faut donc recherche la mauvaise valeur précisément en faisant varier l'heure affichée. Il est aussi possible d'utiliser l'option "Valeurs Abérrantes" pour afficher directement toutes les valeurs qui semblent anormales à HA, à vous de voir ce qui est réaliste ou pas.
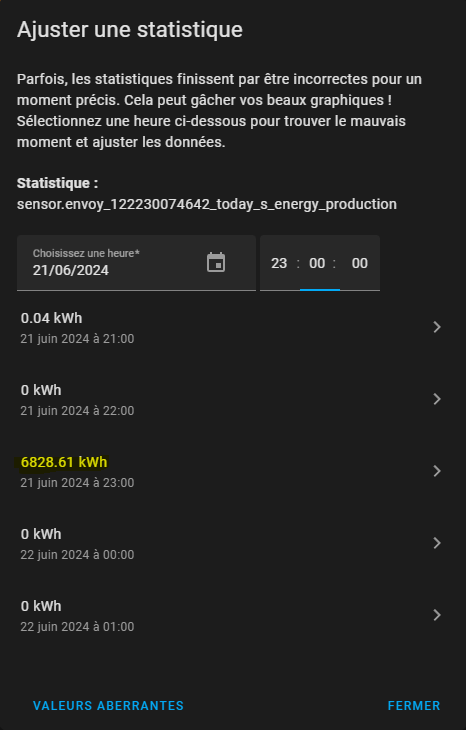
Après avoir repéré la valeur en question, il est possible de cliquer dessus pour afficher le pop-up de correction :
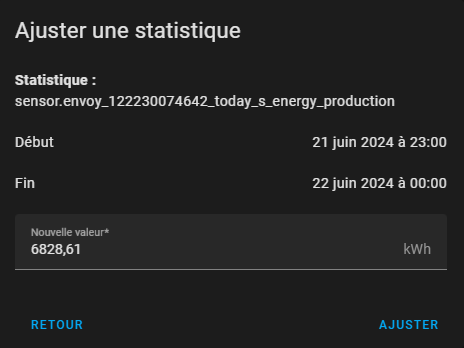
Il suffit de mettre une valeur plus réaliste... ici la production solaire de 23:00 est clairement plutôt "0 kWh"... puis de valider avec le bouton "Ajuster".
En revenant au tableau énergie, on voit que l'affichage est immédiatement corrigée !
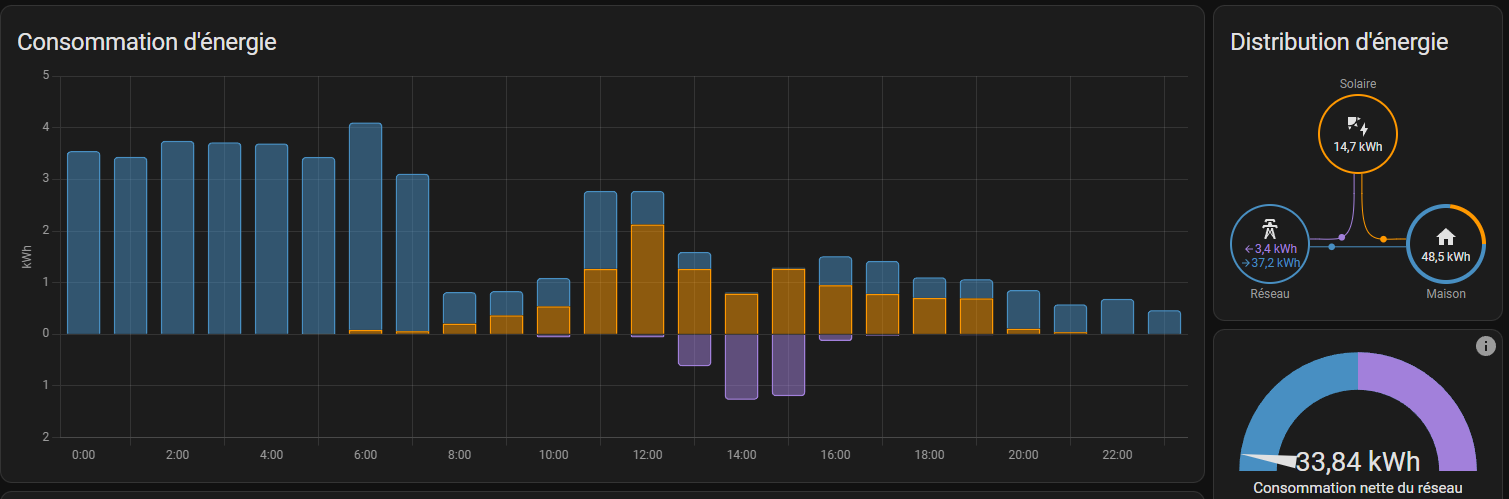
Correction d'entités pour générer les statistiques
Dans certains cas, généralement si vous avez changé votre configuration pour une entité en cours de développement, HA ne génère pas de données statistiques, car le contenu de la base est vue comme incohérente. C'est le cas par exemple si vous changez l'unité de mesure, il ne pourra pas agréger 2 unités différentes. Les outils de développement permettent de détecter ceci aussi.
Différents exemples :
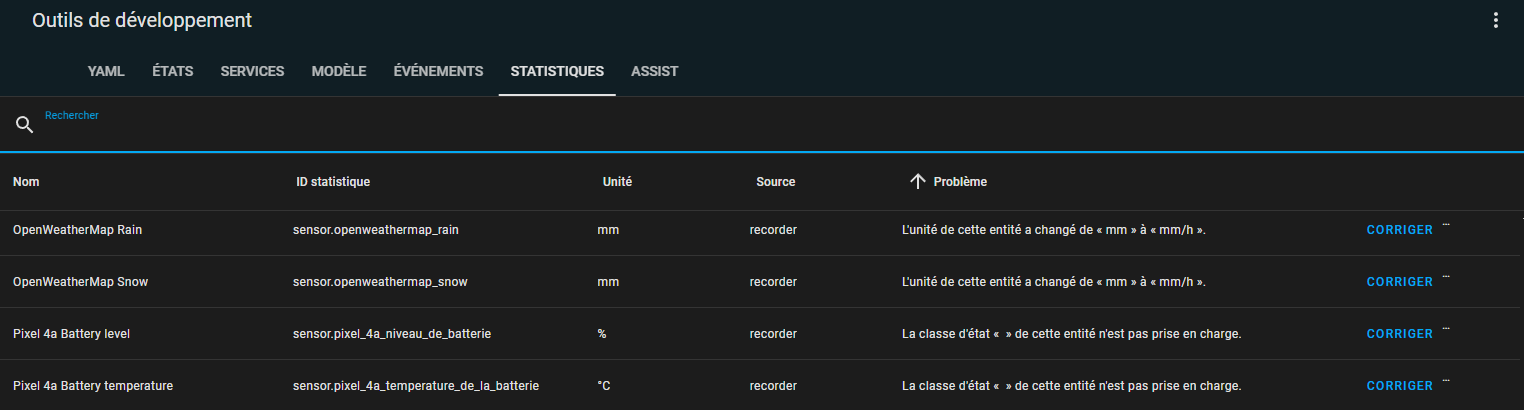
Dans le cas d'une unité changée, il est possible de cliquer sur corriger. A vous de choisir ce que vous voulez faire, suivant votre cas :
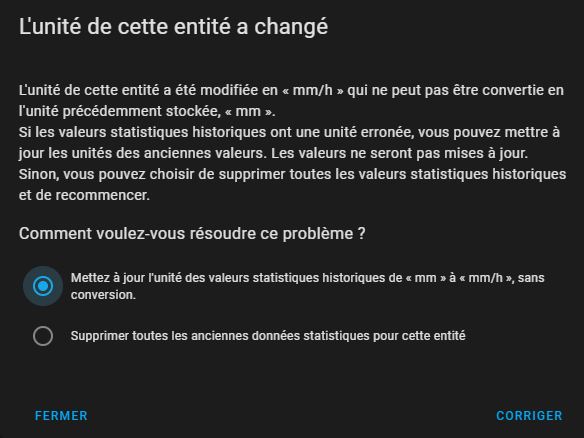
Dans le cas d'une classe non prise ne charge les options possibles sont données en cliquant sur corriger, il faudra choisir l'action à faire ce ne sera pas automatique.

Notions plus avancées
Base de données alternative
Il est possible d'utiliser une autre base de données que la base SQLite par défaut. Cela peut être utile dans certains cas particuliers ou par conviction, même si la base par défaut répond déjà à la majorité des besoins et la performance est plutôt bonne.
Il est en particulier possible de passer par une base SQL MariaDB, grâce à un module complémentaire fourni. L'intérêt est relativement limité car la base resterait sur la même machine que HA. Il n'y a qu'à installer l'add-on et lire les infos pour la configuration.
Certains ajoutent aussi des add-ons comme le duo InfluxDB et Grafana pour maîtriser la gestion de leurs historiques, mais la base InfluxDB ne remplacera pas la base de données de HA, elle vient juste en plus.
Attention aux petits systèmes pas trop puissants, ces add-ons peuvent être gourmands en ressources (NDLR: je ne les aime pas trop).
Pour ceux qui veulent aller plus loin, il est possible d'utiliser une base de données installée sur une machine distante. L'intérêt peut être de gérer le stockage séparément, mutualiser avec une base existante, ou encore réduire l'espace disque de HA, vu que la base est déportée ou encore de directement avoir les données de HA en cas de crash.
A noter que le passage à une autre base fera perdre l'historique.
Pour configurer une base alternative, il faudra passer par la configuration du recorder avec le paramètre
recorder:
db_url: "mysql://<user>:<password>@<ip_db>:<port>/<base>?charset=utf8"
commit_interval: 10
purge_keep_days: 7Structure de la base de données
Voici ci-dessous la liste des tables de la base de données. Les plus importantes commencent par "state" pour les données du recorder et par "statistics" pour les statistiques à long terme.

Requête pour les états d'une entité.
Je vais ici uniquement me pencher sur les tables "state*".
Pour un gain de place, accéder aux valeurs d'une entité ne se fait pas directement. La table "states" contient toutes les données historiques, mais les propriétés et identifiant HA des entités n'y sont pas stockées : il faudra au préalable récupérer une valeur "metadata_id" dans la table "states_meta" pour chaque entité. C'est cette valeur metadata_id qui permettra de retrouver les données d'une entité dans la stable state.
select * from states
where
metadata_id = (select metadata_id from states_meta where entity_id = "sensor.conso_chauffe_eau")
Exemple pour charger toutes les valeurs d'une entité par son nom, une requête imbriquée peut servir.
Requête avec une date
Les dates dans la base sont gérées avec des "timestamps", pas vraiment lisibles par un humain. SQL Fournit la fonction FROM_UNIXTIME pour ceci. (Cette option, n'est potentiellement pas disponible dans SQLite Web)
select * from states
where
metadata_id = (select metadata_id from states_meta where entity_id = "sensor.conso_chauffe_eau")
AND
DATE(FROM_UNIXTIME(last_updated_ts)) = DATE(NOW())Trouver quelles entités polluent votre base
Si votre base de données est trop volumineuse ou si vous êtes simplement curieux, il est possible de lancer une requête qui va vous afficher les entités avec le plus d'enregistrement.
SELECT B.entity_id, count(A.state)
FROM states as A
JOIN states_meta as B on B.metadata_id = A.metadata_id
GROUP BY B.entity_id
ORDER by count(A.state) DESC
Les résultats montrent le nombre d'enregistrements par entité.
Ici par exemple, la première entité à 45000 valeurs pour une base qui contient 7 jours, soit : 45000 / 7 / 24 = 267 par heure. Donc toutes les 14 secondes...
Il faudra donc voir en fonction de la pertinence, si c'est bien utile de garder cette valeur ou s'il faut l'exclure.
Conclusion
Dans cet article, j'ai essayé de faire le tour des choses à savoir sur la base de données de HA ainsi que les principales configurations et recommandations. N'hésitez pas à réagir sur le fil du forum associé. Si de nouvelles informations sont intéressantes à ajouter, je mettrai à jour.
Garder une base de données sa base le plus petite possible a un vrai effet positif sur tous les aspects du système.
À titre d'exemple, ma base de données personnelle est la même depuis 4 ans, elle fait 440 Mo, pour 700.000 lignes dans la table "states", et plus de 550 entités stockées. Je n'ai jamais de problème de sauvegarde ou de restauration, aucun soucis d'upgrade ou de stabilité du système.